コーパスの構築
自分だけの「証拠保管庫」を作る
8. 資料収集で、私たちは「証拠保管庫を利用する探偵」から「自ら現場に赴き、新たな証拠を収集する探偵」へと変身しました。青空文庫から文学作品を、国会会議録から政治家の発言を、YouTubeから字幕データを収集する方法を学びました。
しかし、集めた証拠をそのまま段ボール箱に詰め込んでいては、いざというときに必要な証拠を素早く見つけることができません。優れた探偵は、収集した証拠を丁寧に整理し、いつでも検索・分析できる状態で保管します。
この章では、収集したテキストデータを「分析可能なコーパス」へと変換する技術を学びます。探偵に例えるなら、現場で集めた証拠品を、鑑識課が分析できる状態に整える作業です。この地道な作業を前処理(preprocessing)と呼びます。前処理は華やかな作業ではありませんが、良い研究の土台となる、きわめて重要なステップです。
この章で学ぶこと
- 前処理とは何か、なぜ重要なのかを理解する。
- 正規表現を使ってテキストのノイズを除去できるようになる。
- 分析しやすいファイル構造とメタデータの付け方を身につける。
- 複数ファイルを対象とした検索(grep)ができるようになる。
前処理
なぜ前処理が必要なのか
ウェブから収集したテキストは、そのままでは分析に使えないことが多いです。たとえば、青空文庫からダウンロードした夏目漱石の『坊っちゃん』を開いてみると、以下のような内容が含まれています。
坊っちゃん
夏目漱石
-------------------------------------------------------
【テキスト中に現れる記号について】
《》:ルビ
(例)坊《ぼ》っちゃん
[#...]:入力者注 主に外字の説明や、傍点の位置の指定
(例)Knut Hamsum[#「Knut Hamsum」に傍点]作
-------------------------------------------------------
親譲《おやゆず》りの無鉄砲《むてっぽう》で小供の時から損ばかりしている。
「親譲りの無鉄砲で小供の時から損ばかりしている」という本文を分析したいのに、ルビ(《おやゆず》)や注記([#...])、ヘッダー情報などの「余計なもの」が混じっています。これらを取り除かないと、たとえば「ゆず(柚)」を調べるときに、ルビに含まれている「《おやゆず》りの」の「ゆず」も、調査の対象として含まれてしまいます。このような「余計なもの」をノイズ(noise)と呼びます。ノイズを取り除き、分析に適した形にデータを整える作業が前処理です。
よくあるノイズの種類
ウェブから収集したテキストには、様々な種類のノイズが含まれています。
| ノイズの種類 | 例 | どこで発生するか |
|---|---|---|
| ルビ・注記 | 親譲《おやゆず》り、[#...] | 青空文庫 |
| 余分な空白 | 半角・全角スペースの混在 | 様々なソース |
| タイムスタンプ | 0:15, 1:23 | YouTube字幕 |
| ヘッダー・フッター | 著作権表示、ナビゲーション | ウェブページ |
| 改行の乱れ | 段落途中での改行 | PDF変換、ブログ |
| HTMLタグ | <p>, <br>, <div> |
ウェブページ |
ノイズの種類はデータソースによって異なります。どのようなノイズが含まれているかを事前に把握し、適切な方法で除去することが重要です。
正規表現でノイズを除去する
7. 正規表現—基礎編と7. 正規表現—応用編で学んだ「魔法の呪文」が、ここで大活躍します。
青空文庫のルビを削除する
青空文庫のテキストには、以下のようなルビが含まれています。
このルビを削除して、本文だけを取り出してみましょう。
ルビを消す呪文
ルビのパターンは「《》で囲まれた部分」です。
この呪文の意味を日本語に翻訳すると、以下のようになります。
《→ 開きカッコ(二重山括弧).+?→ 任意の文字の1回以上の繰り返し(最短一致)》→ 閉じカッコ(二重山括弧)
ここで?を忘れると、最長一致になってしまいます。たとえば「親譲《おやゆず》りの無鉄砲《むてっぽう》で」という文字列に対して、《.+》(?なし)を使うと、「《おやゆず》りの無鉄砲《むてっぽう》」まで一気にマッチしてしまいます。
VS Codeを開き、青空文庫のテキストを貼り付けます。Ctrl + H(Mac: Option + Command + F)を押して置換ウィンドウを開きます。
- 検索:
《.+?》 - 置換:(空欄のまま)
- 「正規表現を使用」(
.*ボタン)をオンにする - 「すべて置換」をクリック
ルビが削除され、本文だけが残ります。
青空文庫の注記を削除する
青空文庫には、ルビ以外にも[#...]という形式の注記が含まれています。
この注記も、同じ要領で削除できます。
YouTubeの字幕からタイムスタンプを削除する
8. 資料収集で、YouTubeの文字起こし機能を使ってデータを収集する方法を学びました。コピーした字幕には、以下のようなタイムスタンプが含まれています。
タイムスタンプを消す呪文
HTMLタグを削除する
HTML(Hypertext Markup Language)は、ウェブページの構造や書式などを記述するためのマークアップ言語です。このページに接続すると、HTMLがウェブページにどのように反映されるのかを確認することができます。
8. 資料収集では、国会会議録APIについて言及しました。利用例の中身を覗いてみると、次のような構造をしています。
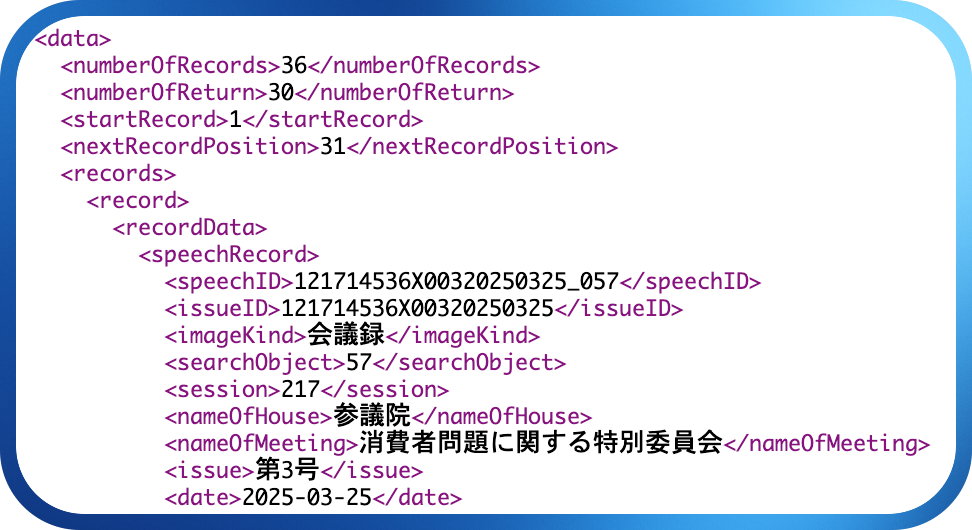
これは厳密に言うとHTMLタグではありませんが、この例を使ってタグを取り除いてみましょう。
タグを消す呪文
まずは、会議録にフライドチキンが含まれている発言例を収集しましょう。すべての文字列を選択して、VS Codeにコピペします。
これでタグを消すことができますが、もっとよい方法を考えてみましょう。この「フライドチキン」の例で必要なのは、「フライドチキン」が入っている発言(スピーチ)のみを取り出すことです。会議録を見ると、発言は<speech>と</speech>に囲まれています。
必要なのは中身
先ほど行った作業を、元に戻しましょう。Ctrl + Zを押すことで、前の状態に戻すことができます。元の状態に戻ったら、以下の正規表現を書いてみましょう。
正規表現を入力した状態で、Alt + Enter (Mac: Option + Enter)を押すと、正規表現にマッチするすべての文字列が選択されます。その状態で、Ctrl + Cでコピーをしましょう。
フォーマットの統一
複数のソースからデータを集めた場合、表記やフォーマットがバラバラになりがちです。分析の前に、これらを統一しておくことが重要です。
| 統一すべき項目 | 例 | 推奨 |
|---|---|---|
| 文字コード | Shift-JIS, EUC-JP | UTF-8に統一 |
| 改行コード | CRLF, LF | LF(\n)に統一 |
| 句読点 | 、, 。 vs ,, . |
どちらかに統一 |
| 数字 | 半角123 vs 全角123 |
半角に統一 |
| 空白 | 半角 |
分析目的に応じて |
文字コードの変換
青空文庫のテキストファイルは、Shift-JISという文字コードで保存されていることがあります。現代のテキスト処理ではUTF-8が標準なので、変換しておくと後々便利です。
文字コードをUTF-8で保存
- VS Codeの右下にある文字コード表示(例:「UTF-8」)をクリック
- 「エンコード付きで保存」を選択
- 「UTF-8」を選択
これで、UTF-8形式のファイルとして保存されます。
改行コードの統一
テキストファイルの改行コードは、OSによって異なります。異なる環境で作成されたファイルを混ぜると、改行がうまく認識されないことがあります。VS Codeでは、右下のステータスバーに改行コードが表示されており、クリックすることで変更できます。
ファイルの整理とメタデータ
フォルダ構造を決める
小規模なコーパスでも、ファイルが増えてくると管理が大変になります。あらかじめフォルダ構造を決めておくと、後から探しやすくなります。
my_corpus/
├── raw/ # 収集したままのデータ
│ ├── aozora/ # 青空文庫
│ │ ├── soseki/ # 夏目漱石
│ │ └── akutagawa/ # 芥川龍之介
│ ├── kokkai/ # 国会会議録
│ └── youtube/ # YouTube字幕
├── cleaned/ # 前処理済みのデータ
│ ├── aozora/
│ ├── kokkai/
│ └── youtube/
└── metadata.csv # メタデータ
このように「生データ」と「前処理済みデータ」を分けておくと、何か問題があったときに元に戻れます。
命名規則を決める
ファイル名には一貫した命名規則を使いましょう。たとえば以下のような規則が考えられます。
作者_作品名_発表年.txt(例:soseki_botchan_1906.txt)ソース_日付_番号.txt(例:kokkai_2024-01-15_001.txt)
日本語のファイル名は避け、半角英数字とアンダースコア(_)やハイフン(-)を使うのが無難です。
メタデータを記録する
メタデータ(metadata)とは、「データについてのデータ」です。テキストそのものではなく、そのテキストがいつ、誰によって、どのような状況で作られたかという情報です。
| メタデータの例 | 内容 |
|---|---|
| 作者 | 夏目漱石 |
| タイトル | 坊っちゃん |
| 発表年 | 1906年 |
| ジャンル | 小説 |
| 収集日 | 2025-12-19 |
| ソース | 青空文庫 |
| URL | https://www.aozora.gr.jp/cards/000148/files/752_14964.html |
メタデータをCSVファイルなどにまとめておくと、後から「1900年代の作品だけを分析したい」「小説とエッセイを比較したい」といったことが簡単にできます。
メタデータのCSVファイルを作る
filename,author,title,year,genre,source
soseki_botchan_1906.txt,夏目漱石,坊っちゃん,1906,小説,青空文庫
soseki_wagahai_1905.txt,夏目漱石,吾輩は猫である,1905,小説,青空文庫
akutagawa_rashomon_1915.txt,芥川龍之介,羅生門,1915,小説,青空文庫
このようなメタデータファイルがあれば、Excelやプログラムで簡単にフィルタリングできます。ここでfilenameは、実際のテキストファイル名と一致している必要があります。PythonやRのようなプログラミング言語でテキストファイルを分析するときには、このfilenameを地図のように使って実際のテキストファイルを読み込みます。つまり、テキストファイル名が、メタデータと実際のテキストをつなげる「IDカード」の役割を担います。
grepで複数ファイルを検索する
コーパスを構築したら、複数のファイルを対象に検索したくなります。VS Codeには、フォルダ内のすべてのファイルを対象に正規表現検索ができるgrep(global regular expression print)機能があります。grepを使うと、複数のファイルを対象として検索した結果を表示させることができます。今回は、夏目漱石の作品を対象に、改行とルビの削除をしてみましょう。
下ごしらえ
- aozorabunko_textにある「Download ZIP」をクリックして、テキストファイルをダウンロード
- 「Download ZIP」を解凍すると「aozorabunko_text-master」というフォルダが現れるので、中に入って「cards」→「000148」フォルダを探す(夏目漱石の作者番号)
解凍には時間がかかる
Macの場合はすぐ解凍ができますが、Windowsの場合、「すべて展開」をすると5〜10分程度かかることがあります。こういうときには、7-Zipをインストールして解凍するといいでしょう。インストールをした場合には、以下の手順で、7-Zipで解凍することができます。

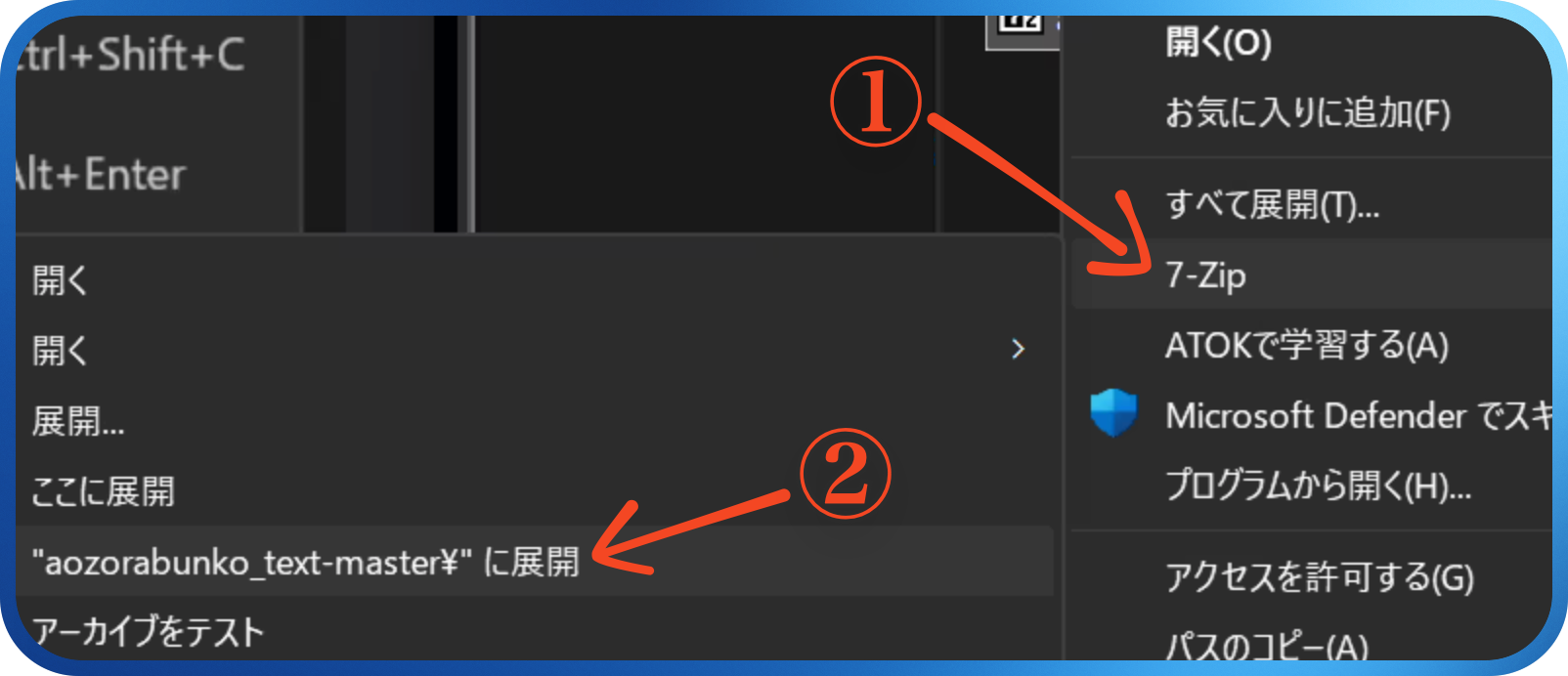
- VS Codeで「ファイル」→「フォルダを開く」(あるいは
Ctrl + O) - 解凍した「000148」フォルダを選択
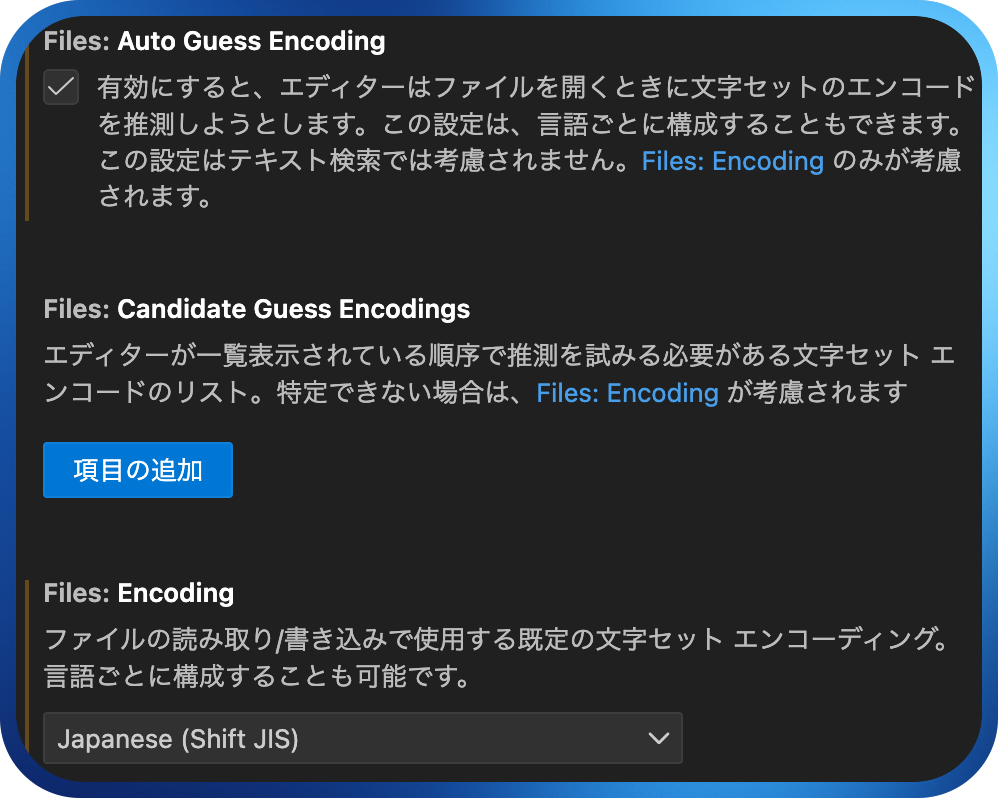
文字化けする人はCtrl+,で設定を開き、「encoding」を検索して以下のように設定を変更
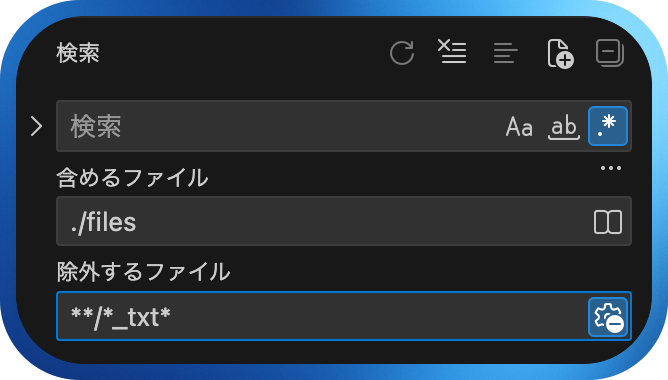
読み込んだフォルダの中にある「files」を右クリックして「フォルダ内を検索」を選択します。そうすると、検索窓に切り替わります。そこに正規表現を入力することで、読み込んだフォルダの中にあるすべてのファイルを対象として検索できます。
最大検索件数の引き上げ
基本的にVS Codeでは、検索結果の上限が「20,000」となっています。これを、十分に大きい数字に変えてみましょう。
Ctrl + Shift + C、または、左下にある歯車(設定)にある「コマンドパレット」を選択します。- 窓が出てくるので「ユーザー設定を開く」と入力し、選択します。
- 今度は「検索結果の最大数」と入力して「Search: Max Results」にある数字を「1000000」に変更して、「✖」を押して閉じます。
ちゃんと20,000以上の検索結果が出るのか、grep機能を使って試してみましょう。grepで100万件以上を表示させたい場合には、テキストエディタではなく、10. Colabの活用—基礎編で触れるPythonを利用した方がいいでしょう。
では、クリーニングが終わったテキストファイルを対象として、オノマトペを検索してみましょう。「エディターで開く」を選択すると、より大きい画面で見ることができます。画面には、「マッチした件数」「ファイル名」「行番号」「マッチした文字列」「前後の文脈」などの情報が表示されます。この中で「前後の文脈」は、「コンテキスト行を切り替える」ボタンを押すことで、マッチした結果のみを表示させることができます。
マッチした文字列だけ切り取る
今までやってきた操作は、検索結果を「行」レベルで取り出します。しかし、正確に正規表現にマッチした「文字列のみ」を取り出したい場合もあるでしょう。たとえば、オノマトペ(っぽいもの)を検索して、行レベルで取り出すのではなく、その部分だけを切り取る方法です。
切り取り
今回は、3文字以上のひらがなが、2回繰り返されている例を探してみましょう。
- 検索結果が表示されているところにカーソルを置き、
Ctrl + Shift + L(Mac:command + Shift + L)を押しましょう。すると、正規表現にマッチした文字列だけが選択されます。 - その状態で、コピー(
Ctrl + C)をしておきます。 - 新しいテキストファイルを作って貼り付けると、正規表現にマッチした文字列だけが残ります。
💻 やってみよう!
特定作家の作品をクリーンアップ
ここまで、夏目漱石の作品を対象に作業を行いました。ここでは、夏目漱石以外の作家を一人選び、その人の作品すべてを対象として、作業を行ってみましょう。オノマトペ以外に、ちょっと気になっている表現を正規表現で検索して、切り取ってみましょう。
2026年明けスペシャル
データの前処理の最終段階として、形態素解析をする必要があります。もちろん、分析に必要な文字列の抽出に、正規表現を利用することで対応できる場合もありますが、限界があります。形態素解析済みの文字列であれば、正規表現と組み合わせて、より詳細な調査・分析ができるようになります。
まずは、4. 形態素と形態素解析での記憶を呼び戻して、Web茶まめを使って形態素解析をやってみましょう。